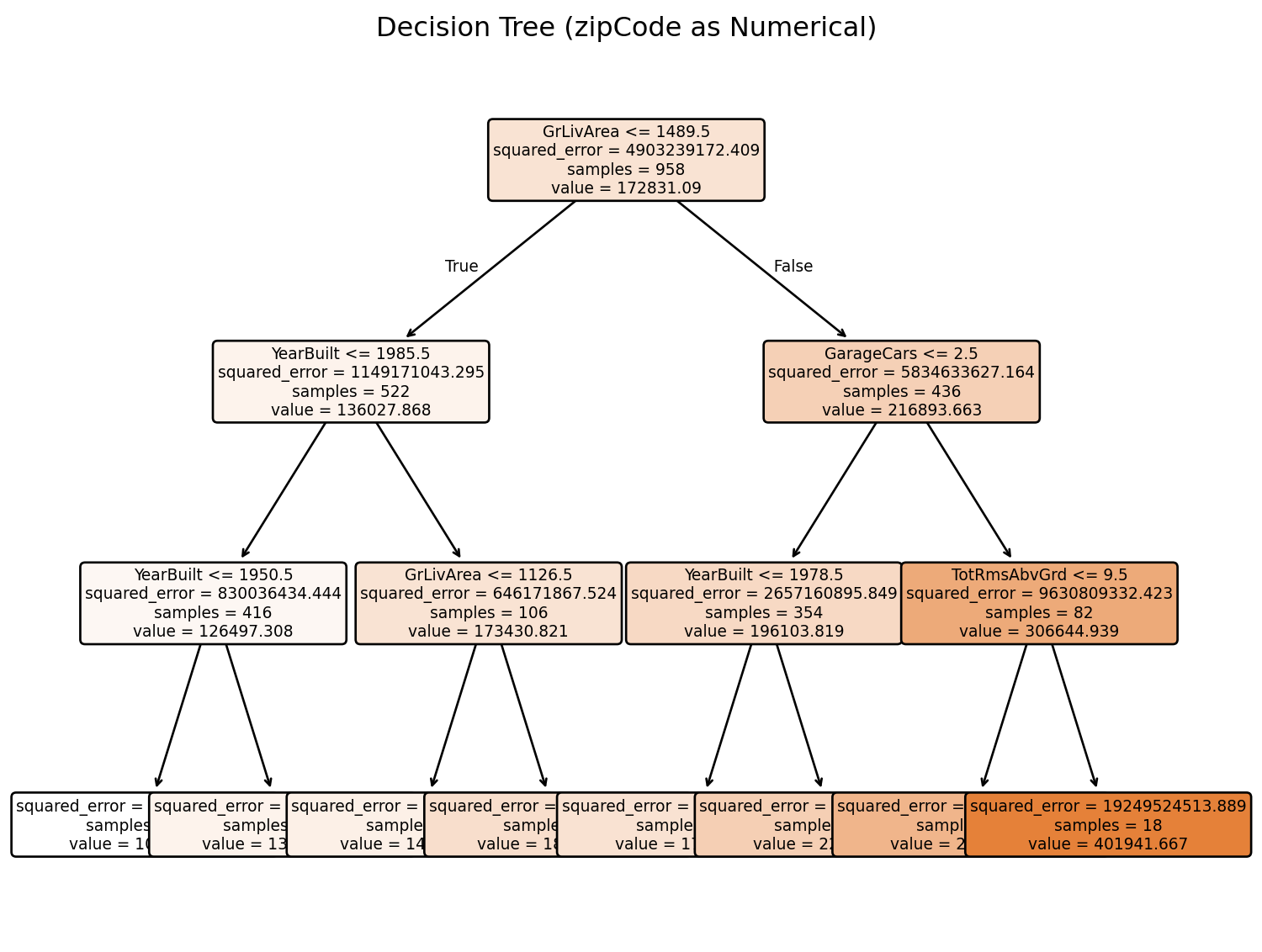
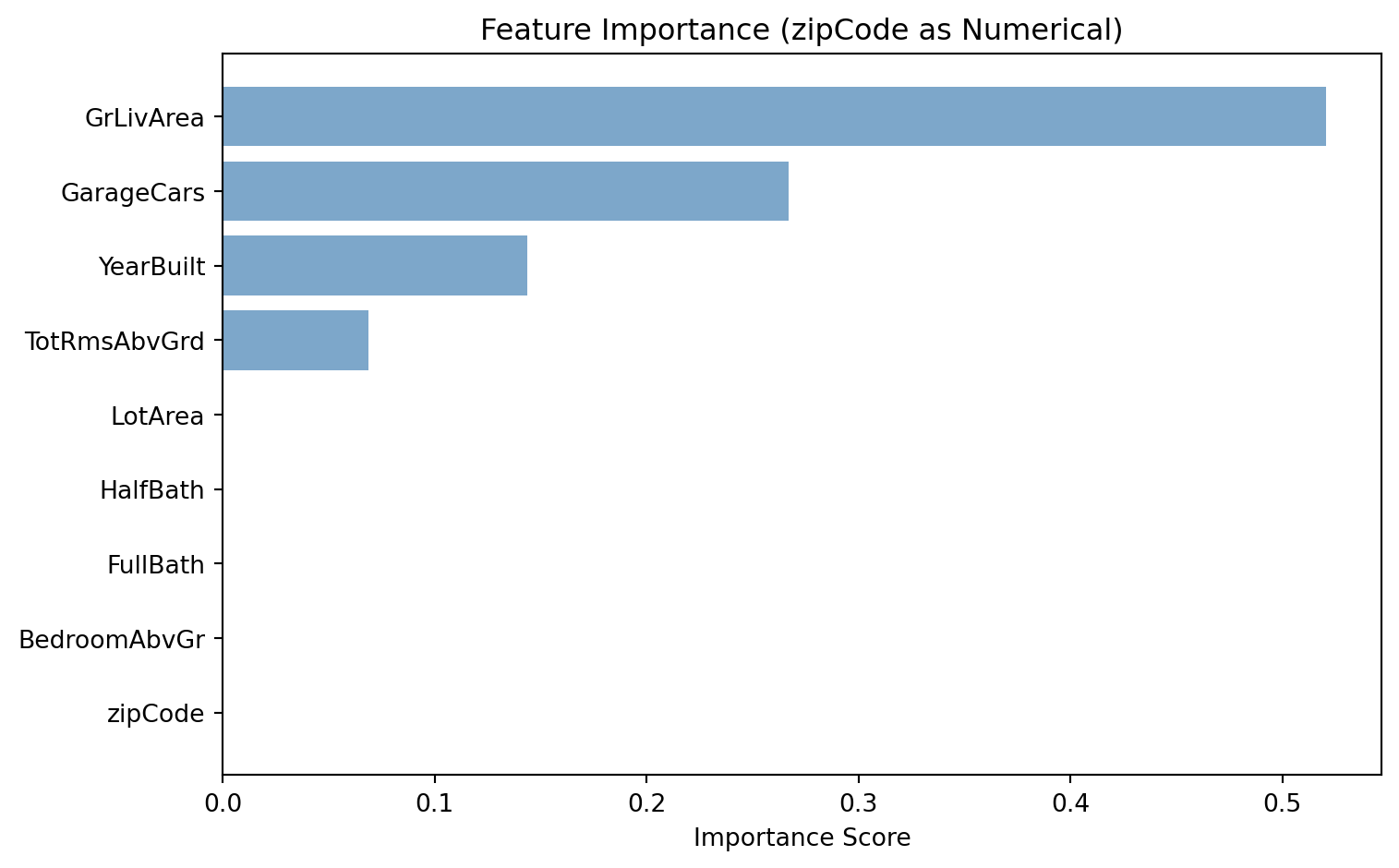
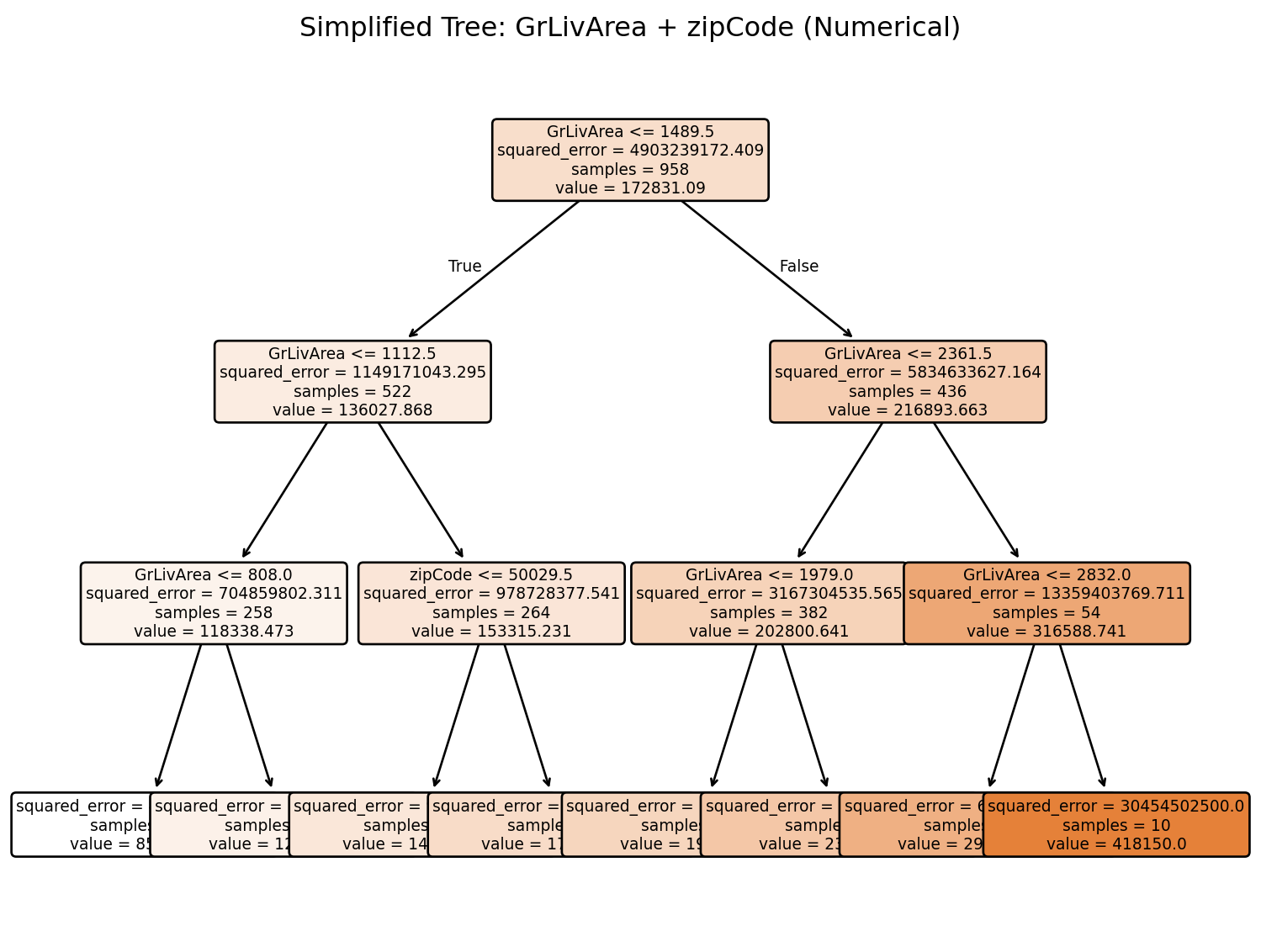
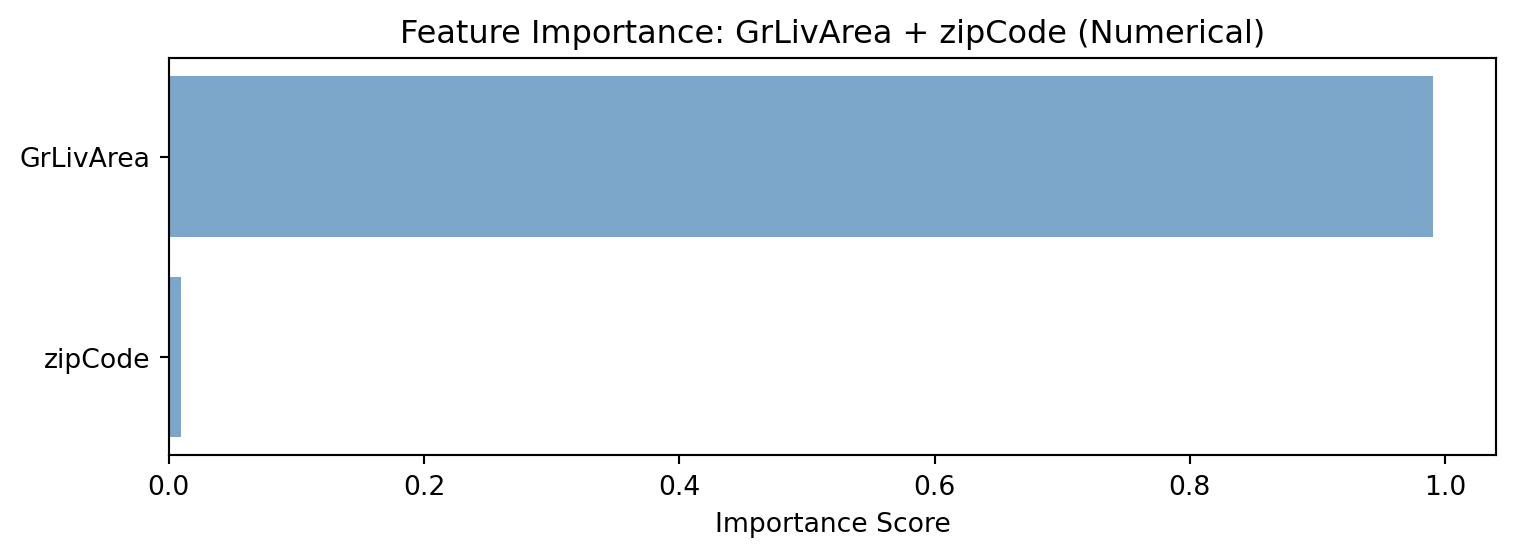
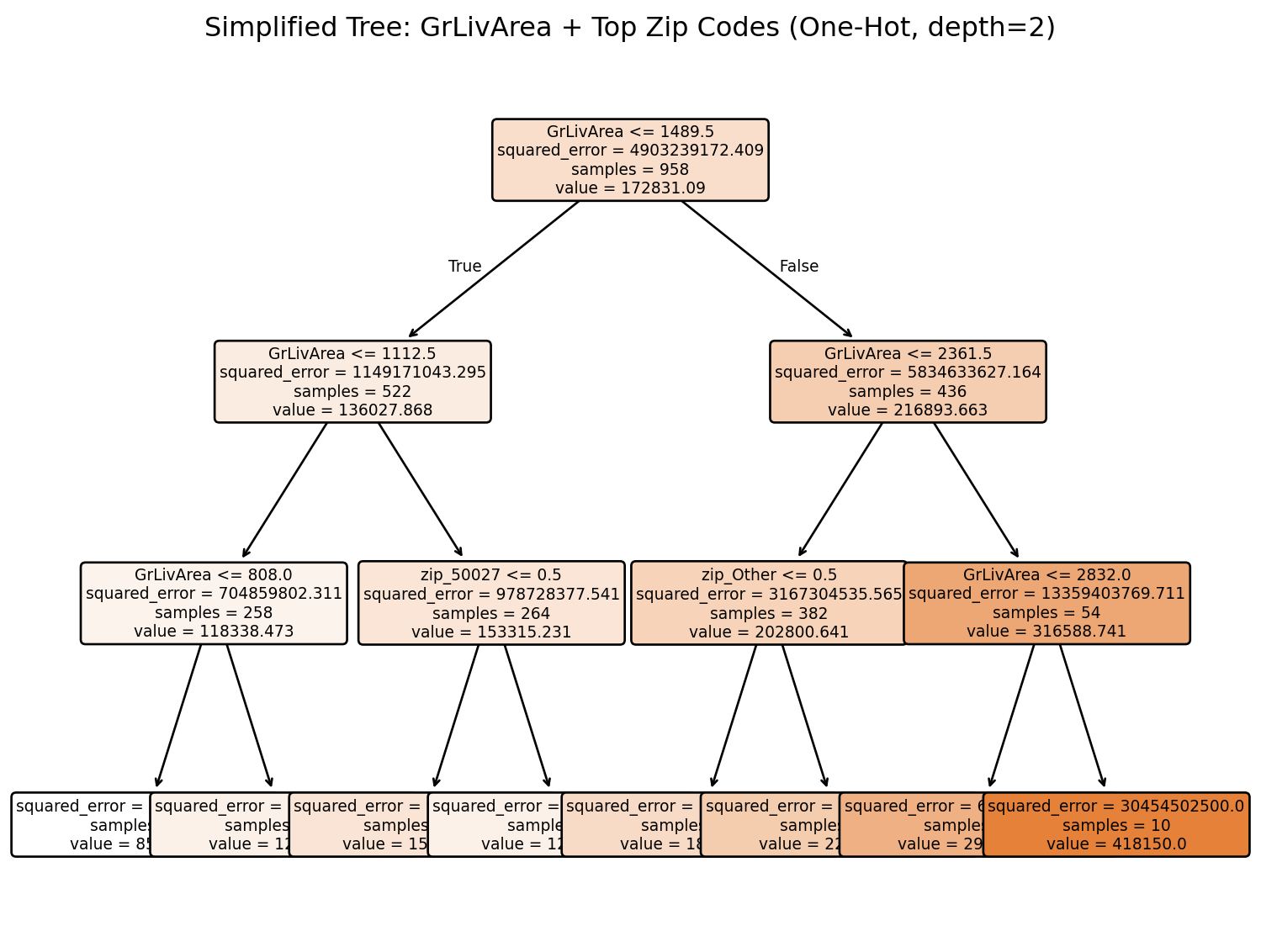
The problem: When we encode categorical variables as numerical values (like 1, 2, 3, 4…), decision trees treat them as if they have a meaningful numerical order. This can completely distort our analysis.
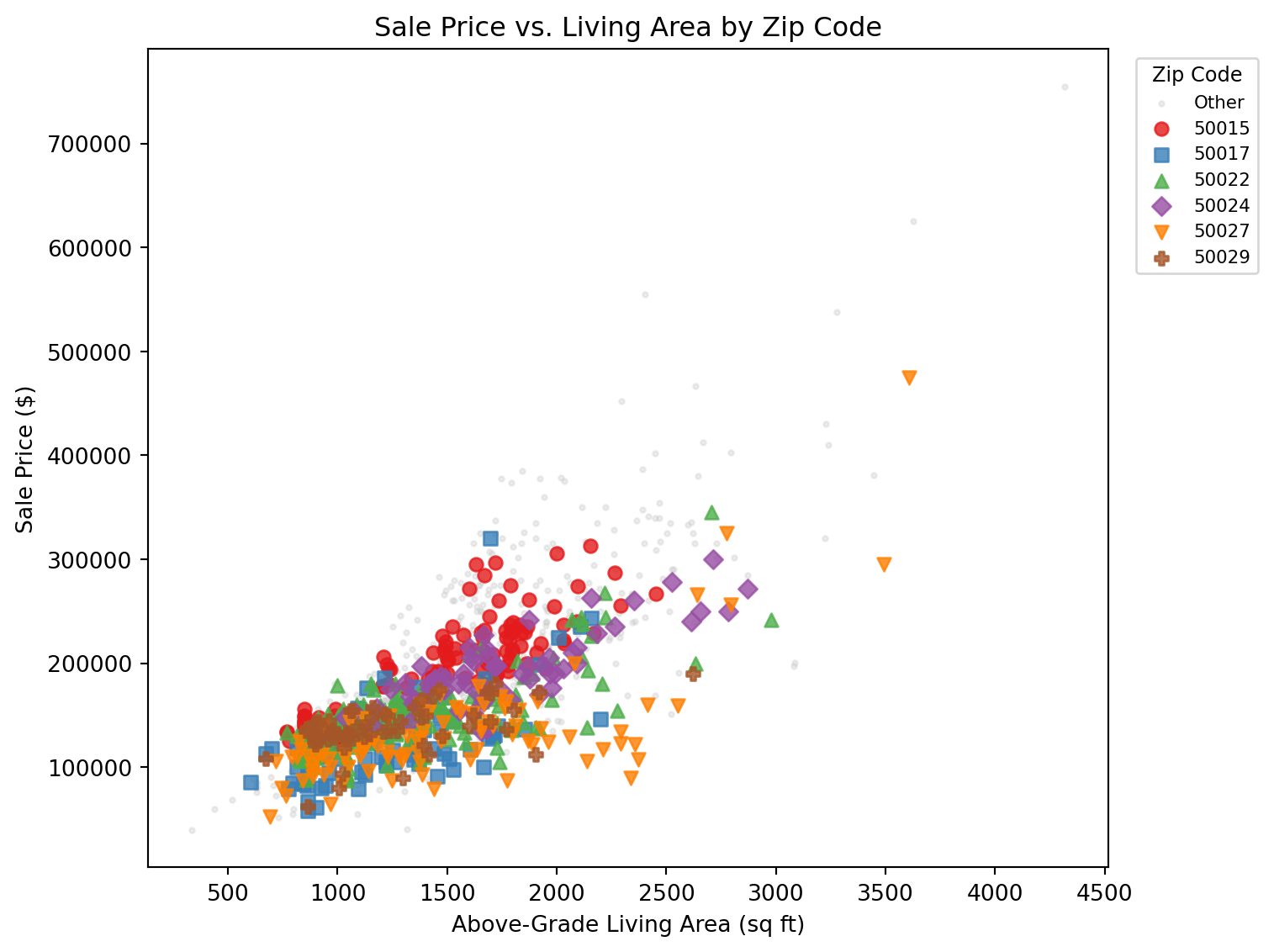
The Real-World Context: In real estate, we know that neighborhood quality, house style, and other categorical factors are crucial for predicting home prices. But if we encode these as numbers, we might get misleading insights about which features actually matter most.
The Devastating Reality: Even sophisticated machine learning models can give us completely wrong insights about feature importance if we don’t properly encode our variables. A categorical variable that should be among the most important might appear irrelevant, while a numerical variable might appear artificially important.